-
2편: 유사도 검색과 벡터 인덱싱Open Source/VectorDB 2025. 6. 5. 16:03반응형
벡터 데이터베이스의 핵심 기능 – 유사도 검색
벡터 DB의 가장 중요한 기능은 비슷한 데이터를 빠르게 찾는 것입니다. 이를 유사도 검색(similarity search) 혹은 근접 이웃 검색(nearest neighbor search)라고 합니다.
예를 들어, 문장 “벡터 DB 배우고 싶어요”의 벡터를 기준으로, 비슷한 의미의 다른 문서나 문장을 찾아 주는 것 입니다.
유사도 계산 방식
유사도를 계산할 때는 보통 아래 세 가지 방식이 많이 쓰입니다.
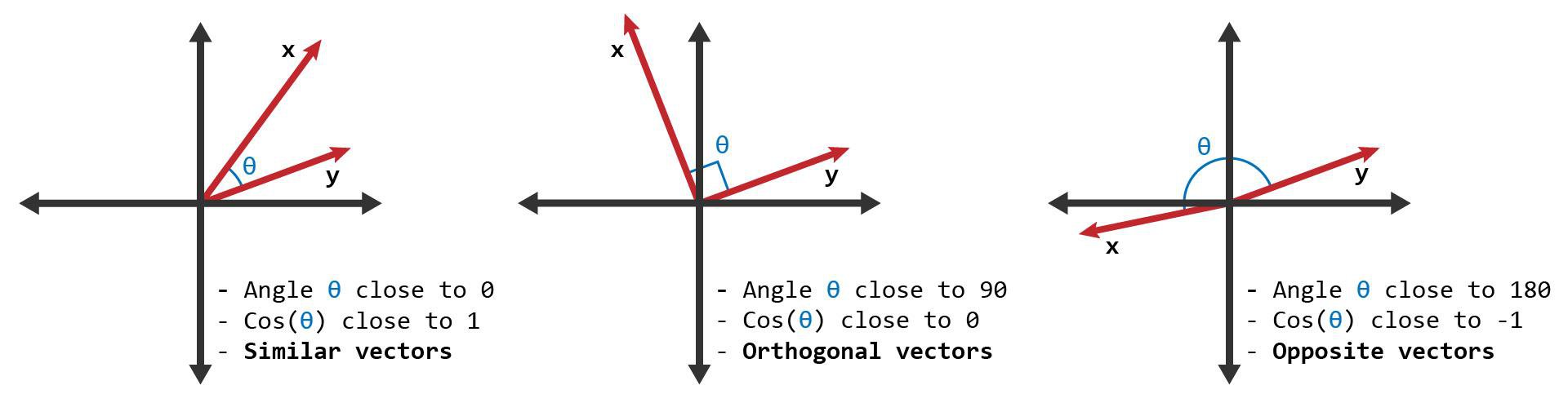
- 코사인 유사도 (cosine similarity)
- 두 벡터의 방향(각도)을 기준으로 유사도를 계산합니다.
- $\cos(\theta) = \frac{{\mathbf{v}_1 \cdot \mathbf{v}_2}}{{|\mathbf{v}_1| |\mathbf{v}_2|}}$
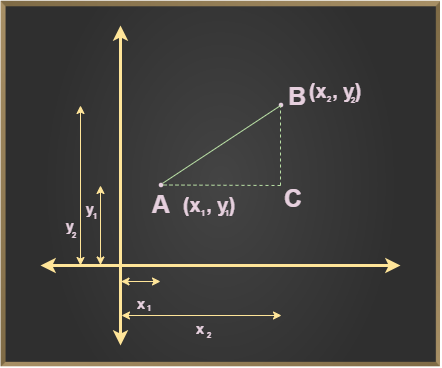
- 유클리드 거리 (Euclidean distance)
- 두 벡터 간의 실제 거리(직선 거리)를 계산합니다.
- $\mathbf{v}1 = (v{1,1}, v_{1,2}, \dots, v_{1,n})$
- $\mathbf{v}2 = (v{2,1}, v_{2,2}, \dots, v_{2,n})$
- $d(\mathbf{v}1, \mathbf{v}2) = \sqrt{\sum{i=1}^n (v{1,i} - v_{2,i})^2}$
- 내적 (dot product)
- 두 벡터를 그대로 곱해서 나온 값으로 유사도를 봅니다.
- $\mathbf{v}1 \cdot \mathbf{v}2 = \sum{i=1}^n v{1,i} \cdot v_{2,i}$

검색 속도 문제와 인덱싱
벡터의 차원이 수백~수천 개가 되면, 모든 데이터를 일일이 비교하면 검색 속도가 너무 느려집니다.
이를 해결하기 위해 벡터 인덱싱 기법을 사용합니다.
벡터 인덱싱의 개념
인덱싱은 데이터를 빠르게 찾을 수 있도록 미리 만들어둔 "지도" 같은 역할 입니다.
- RDB의 인덱스처럼, 벡터 DB도 비슷한 벡터끼리 묶어둔 구조를 미리 만들어둡니다.
- 검색할 때 이 인덱스를 활용해서 필요한 데이터만 빠르게 확인합니다.
대표적인 인덱싱 기법
Brute-force (Full scan)
- 모든 벡터를 일일이 비교 (가장 정확하지만 느림)
Approximate Nearest Neighbor (ANN) 기법
- 정확도를 조금 포기하고, 훨씬 빠른 검색 속도를 얻는 방식
ANN 알고리즘 예시:
- HNSW (Hierarchical Navigable Small World)
- 그래프 기반 인덱싱 방식으로, 데이터 간의 연결관계를 계층적으로 만들어서 빠르게 비슷한 벡터를 탐색할 수 있습니다.
- IVF (Inverted File Index)
- 벡터들을 여러 개의 클러스터(버킷)로 나눈 뒤, 검색할 때는 클러스터부터 좁혀가며 검색 속도를 빠르게 합니다.
- PQ (Product Quantization)
- 벡터를 여러 부분으로 나누고(서브 벡터), 각 부분을 근사적으로 양자화해서 저장 공간을 줄이고 검색 속도를 올립니다.
실제 검색 예시 (Python 코드)
아래는 Python에서 코사인 유사도를 간단히 계산하는 예시입니다.
from sklearn.metrics.pairwise import cosine_similarity import numpy as np # 예제 벡터 2개 v1 = np.array([0.1, 0.2, 0.3]) v2 = np.array([0.2, 0.1, 0.4]) # 코사인 유사도 계산 similarity = cosine_similarity([v1], [v2]) print(similarity[0][0])마무리
- 유사도 검색은 벡터 DB의 핵심 기능
- 코사인 유사도, 유클리드 거리, 내적 등으로 유사도를 계산
- 인덱싱 기법(특히 ANN)이 없으면 속도가 너무 느려짐
- ANN 인덱싱으로 속도와 정확도를 절충
다음 글에서는…
다음 글에서는 대표적인 벡터 DB 솔루션(Pinecone, Weaviate, Milvus 등)을 비교해보려 합니다.
반응형'Open Source > VectorDB' 카테고리의 다른 글
1편: 벡터 데이터베이스의 개념과 필요성 (1) 2025.06.03 - 코사인 유사도 (cosine similarity)